Protocol Overviewを読む

Start hereって書いてあるので多分ここからStartするのが良さそう
DeepLでポン
>プロトコルの概要#
> Authenticated Transfer Protocol、通称ATPは、大規模な分散型ソーシャルアプリケーションのためのプロトコルである。本資料では、ATプロトコルの背景にある考え方を紹介します。
>
> Identity#
> ユーザーは、ATプロトコルのドメイン名で識別されます。これらのドメインは、ユーザーのアカウントとそのデータを保護する暗号化URLにマッピングされます。
>
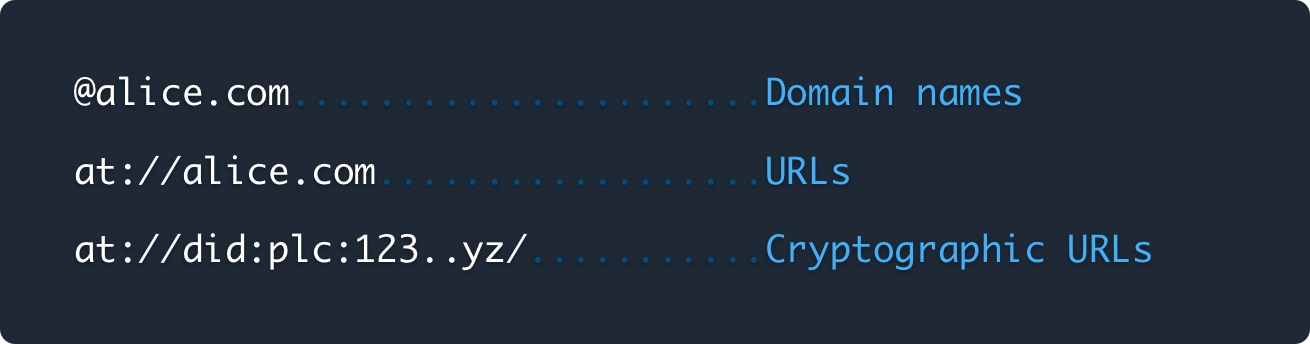
暗号化URL, Cryptographic URLsとは?
これはDNS的なURLとは関係ないのかな..?
シンプルにdidに基づくURLを暗号化URLと表現してるだけな気はする
>
> データリポジトリー#
> ユーザーデータは、Signed Data Repositoriesで交換されます。このリポジトリは、投稿、コメント、「いいね!」、フォロー、メディアブロブなどを含むレコードの集合体である。
>

なるほど、signsってのは普通にIDとパスワードのペアの認証のことかな?
>
> フェデレーション#
> ATPは、フェデレーテッド・ネットワーキング・モデルでリポジトリを同期します。ネットワークが便利に使え、確実に利用できるようにするために、フェデレーションが選ばれました。コマンドは、HTTPS + XRPCを使用してサーバー間で送信されます。
>
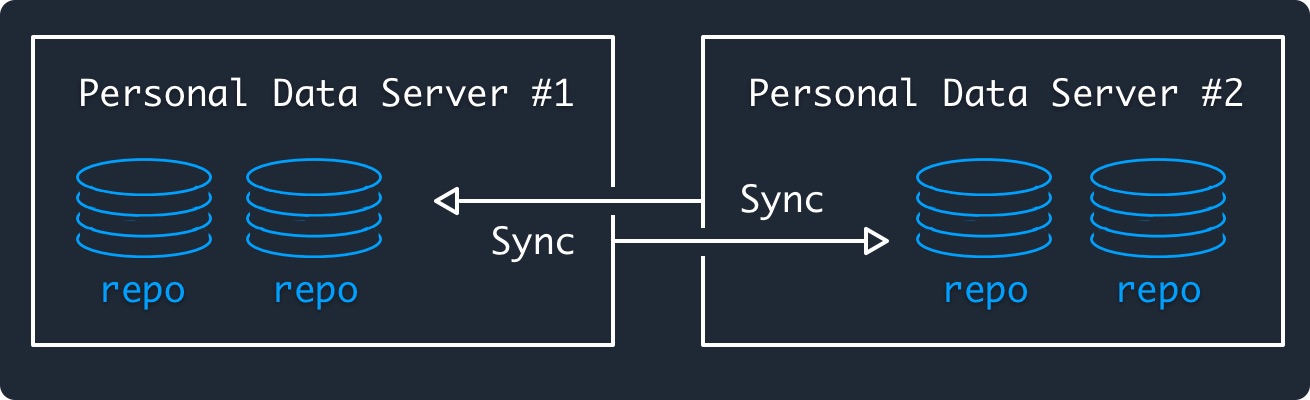
これもATProtocolの一部らしい
色々な人のrepoを持ったサーバー同士が通信する感じか
これはNostrと同じだな
>
> 相互運用#
> Lexiconと呼ばれるグローバルなスキーマネットワークは、サーバー間の呼び出しの名前と動作を統一するために使用されます。サーバーは、ユーザーリポジトリを同期するためのコアATP Lexiconや、基本的な社会的動作を提供するためのBsky Lexiconなど、機能セットをサポートする「Lexicon」を実装します。
>
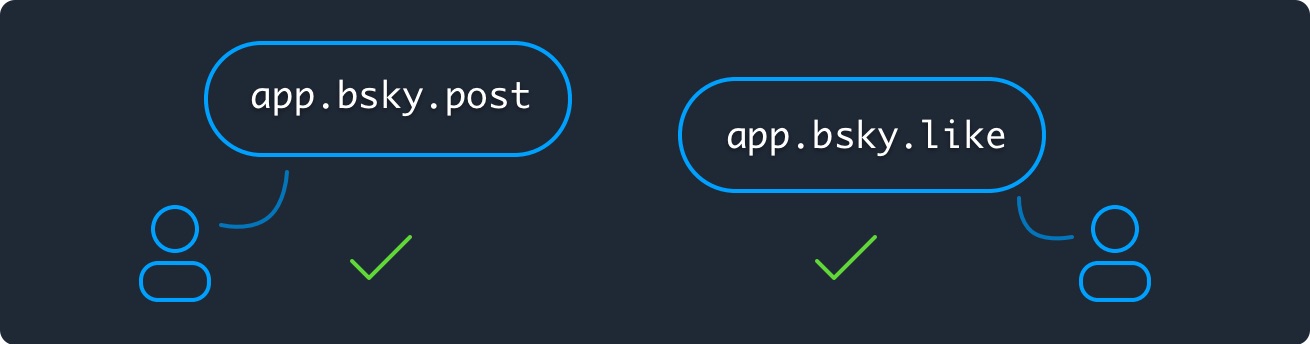
全然わからん
ベースのプロトコルの上に乗っかるプラグイン的なプロトコル、みたいな..?
Lexiconという言葉自体は語彙、語彙目録という意味らしい
> Webがドキュメントを交換するのに対し、ATプロトコルはschematic and semantic Informationを交換し、異なる組織のソフトウェアが互いのデータを理解することを可能にします。これにより、ATPクライアントはサーバーに依存しないユーザーインターフェースを自由に作成でき、コンテンツを閲覧する際にレンダリングコード(HTML/JS/CSS)を交換する必要がなくなります。
データを通信しているからインターフェースは好きにできるよ、ということか
これはそうね
クライアントは好きなの使いな、という話かな
Twitterはデータとインターフェースが一体化されているから規制出来てしまう
>
> スケール#を実現する
> ATPでは、「スモールワールド」と「ビッグワールド」のネットワーキングを区別しています。スモールワールドネットワーキングは個人間の活動を包含し、ビッグワールドネットワーキングはユーザーの個人的な交流以外の活動を集約しています。
>
> スモールワールド:メンション、リプライ、DMなど、特定のユーザーを対象としたイベントの配信や、フォローグラフに応じたデータセットの同期。
> ビッグワールド:大規模な指標(いいね、リポスト、フォロワー)、コンテンツ発見(アルゴリズム)、ユーザー検索。
なるほど、なんか面白くなってきた
PDS同士のP2P?の通信でスモールスケールかつ重い情報の交換はやる
軽いけどスケールが大きい情報はCrawling Indexerが集約する
という感じかな?合理的
> パーソナルデータサーバー(PDS)はスモールワールドのネットワーキングを担当し、インデックスサービスは別途ネットワークをクロールしてビッグワールドのネットワーキングを提供します。
>
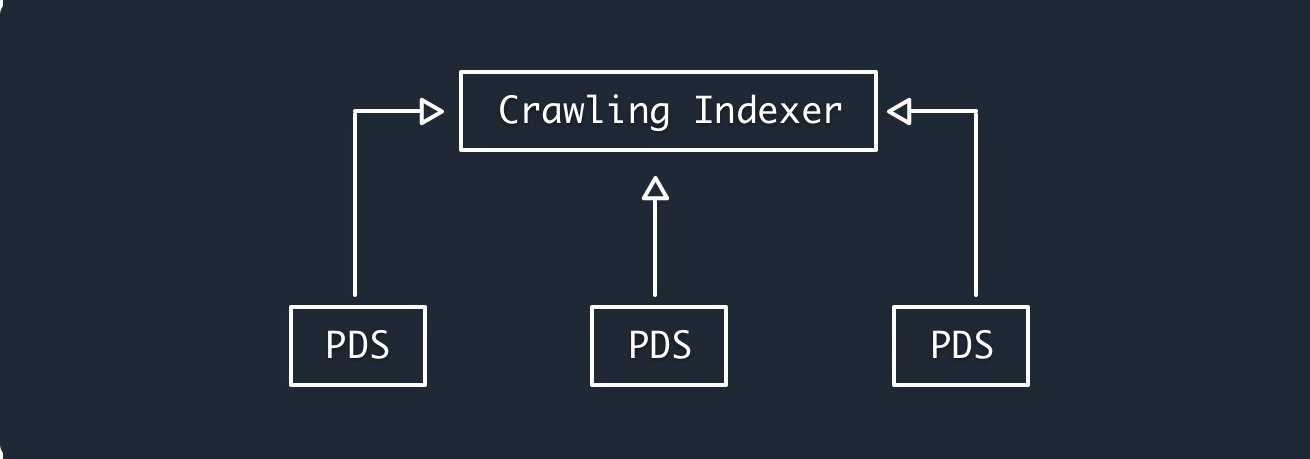
>
> スモールワールド/ビッグワールドの区別は、スケールの大きさと同時に、ユーザーの高度な選択を実現することを目的としています。
>
> アルゴリズムによる選択#
> ウェブ検索エンジンと同様に、ユーザーは自由にインデクサを選択することができます。各フィード、ディスカバリーセクション、検索インターフェースは、サードパーティーのサービスから提供されながら、PDSに統合されています。
>

なるほど、Crawling Indexerは検索エンジン的な位置付けなのか
改めて名前読んだらCrawlしてIndexするのは検索エンジンそのままだw
フォローしてるユーザーのPDSはP2Pでとってきて、検索タブとかからの情報取得はCrawling Indexerがやるみたいな認識で良いのかな
「PDSに統合される」とは?
>
> アカウントポータビリティ#
> パーソナルデータサーバーは、全体がオフラインになったり、特定のユーザーに対するサービスを停止したりと、いつでも障害が発生する可能性があると想定しています。ATPの目標は、サーバーの関与なしに、ユーザーが自分のアカウントを新しいPDSに移行できるようにすることである。
>
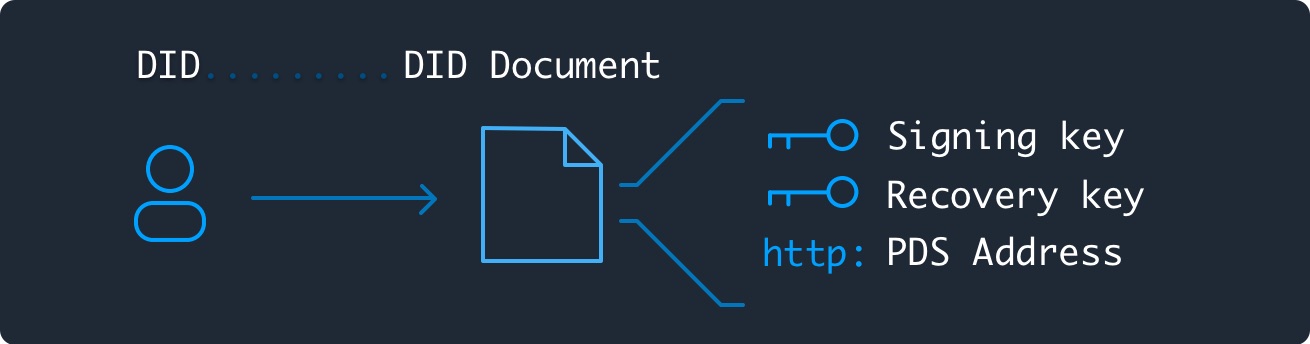
> ユーザーデータは署名されたデータリポジトリに保存され、DIDによって検証される。DIDは基本的にユーザー証明書のレジストリであり、TLS証明書システムに似ているところがある。DIDは、安全で信頼性が高く、ユーザーのPDSから独立していることが期待されている。
>
DIDは、nostrの秘密鍵的な感じで使っているのかな?
>
> 各DID Documentは、署名鍵と回復鍵の2つの公開鍵を公開する。
>
> 署名キー。DID Documentとユーザーのデータリポジトリへの変更を証明する。
> リカバリーキー。72時間以内であれば、署名鍵を上書きすることができる。
> 署名鍵はPDSがユーザーのデータを管理するために預けられるが、回復鍵はペーパーキーなどとしてユーザーが保存する。これにより、ユーザーは元のホストの手を借りずに、新しいPDSにアカウントを更新することが可能になります。
これはまあ本質ではないけど実用上大事な仕様かな
nostrはそういうところカバーできていない印象
>

> ユーザーのデータのバックアップは、バックアップとしてクライアントに永続的に同期されます(利用可能なディスク容量に依存)。PDSが予告なく消滅した場合、ユーザーはDID Documentを更新し、バックアップをアップロードすることで、新しいプロバイダーに移行することができるはずです。
これは良い
こういう時に過去ツイートを自由に書き換えたりできたりしないのかな
別に本人なら好きにしたら良いじゃんみたいな思想?
でもRT数とかは書き換えらたらまずいだろうし、その辺りの情報の正しさの保証がどうなっているのか掴めていない
>
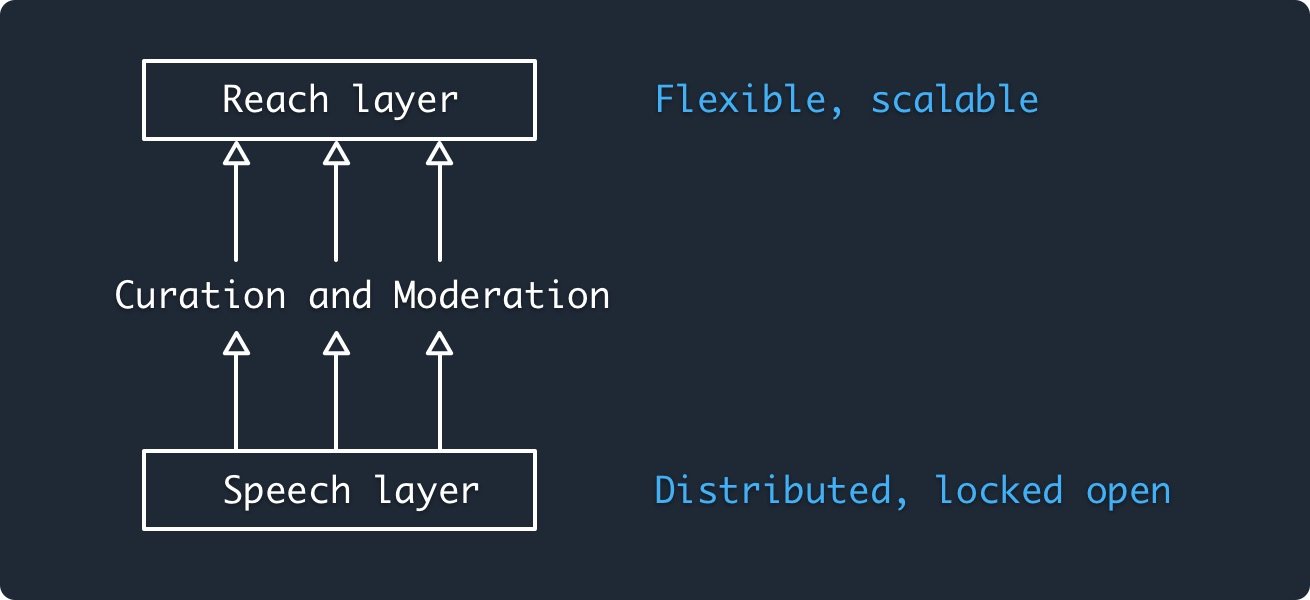
> スピーチ、リーチ、そしてモデレーション#。
> ATPのモデルは、スピーチとリーチは2つの別々のレイヤーであるべきで、互いに協力し合うように構築されています。スピーチ」レイヤーは中立的な立場を保ち、権限を分散させ、誰もが発言できるように設計されています。リーチ」レイヤーはその上に位置し、柔軟性を備え、拡張できるように設計されています。
>
>
> ATPのベースレイヤー(Personal Data Repositories and Federated Networking)は、誰もが自由に参加できる言論のための共通の空間を作り出します。これは、誰でもウェブサイトを立ち上げることができるウェブに似ています。そして、インデックスサービスは、検索エンジンに例えられるように、ネットワークからコンテンツを集約することでリーチを可能にします。
なるほど
> 仕様
> 5つの主要な仕様が@-protocolのv1を構成しています。これらの仕様は以下の通りです。
>
> 認証型転送プロトコル
> クロスシステムRPC(XRPC)
> レキシコン・スキーマ
> ネームスペースID(NSID)
> DID:プレースホルダー(did:plc)
> これらのスペックは、依存関係の3つのレイヤーに整理することができます。
>
>

>
> ここから先は、ガイドやスペックを読み進めることができます。
>
> www.DeepL.com/Translator(無料版)で翻訳しました。
npm:@at-proto/api にblueskyの仕様も入ってるBSky LexiconとかいうものがATProtocolの説明で出てくるのがよく分からんかった
ATProtocolはBlueskyとは仕様上独立しているものだと思っていたので
bsky lexicon (app.bsky.~~) と、現在のBlueskyベータ版(PDS + Crawling Indexer + iOS/Webクライアント)は異なるレイヤーにあるということかな
bsky lexiconはプロトコルの一部