GPT-4o
2024/5/14
> @OpenAI: Say hello to GPT-4o, our new flagship model which can reason across audio, vision, and text in real time: http://openai.com/index/hello-gpt-4o/
>
> Text and image input rolling out today in API and ChatGPT with voice and video in the coming weeks.
>
OpenAIは2024年5月13日、GPT-4oという新しい旗艦モデルを発表しました。主なポイントは以下の通りです。
GPT-4oは、テキスト、音声、画像を組み合わせた入力を受け付け、同様の組み合わせで出力できる。リアルタイムで処理可能。
英語とコードではGPT-4 Turboと同等の性能だが、英語以外のテキストではかなり改善。また、処理速度が速く、コストも50%安い。
従来のベンチマークでは、テキスト、推論、コーディングの知能はGPT-4 Turboレベル。多言語、音声、視覚の能力は新記録を達成。
設計段階からモダリティ全体でセーフティを組み込み、音声出力に対する新しい安全システムも導入。外部の専門家によるレッドチームテストも実施。
GPT-4oのテキストと画像の機能はChatGPTで提供開始。APIでも利用可能になり、GPT-4 Turboより速度、コスト、レート制限の面で優位。 `
> @sama: it is a very good model (we had a little fun with the name while testing)
>
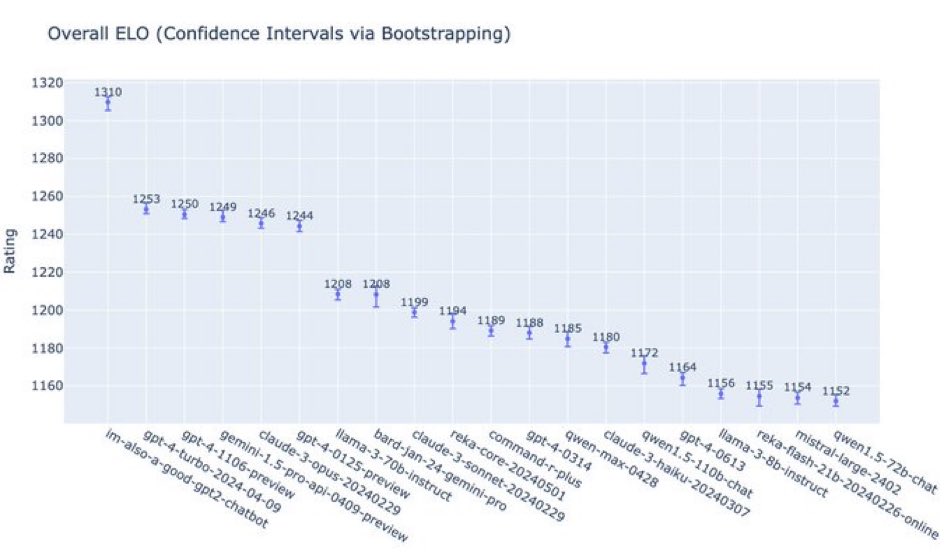
gpt2-chatbotは実はGPT-4o

あった