ScrapboxからWorkFlowyにデータを移すためのUserScript
ページ一つひとつのAPIを叩いて回るので、数が多いとむちゃくちゃ待たされます。
例
ハッシュタグ的なページ(リンクはされているが、ページの中身の記述が無い、カテゴリ的に機能しているページ)で右のボタン(ランダムボタンの下)を発動
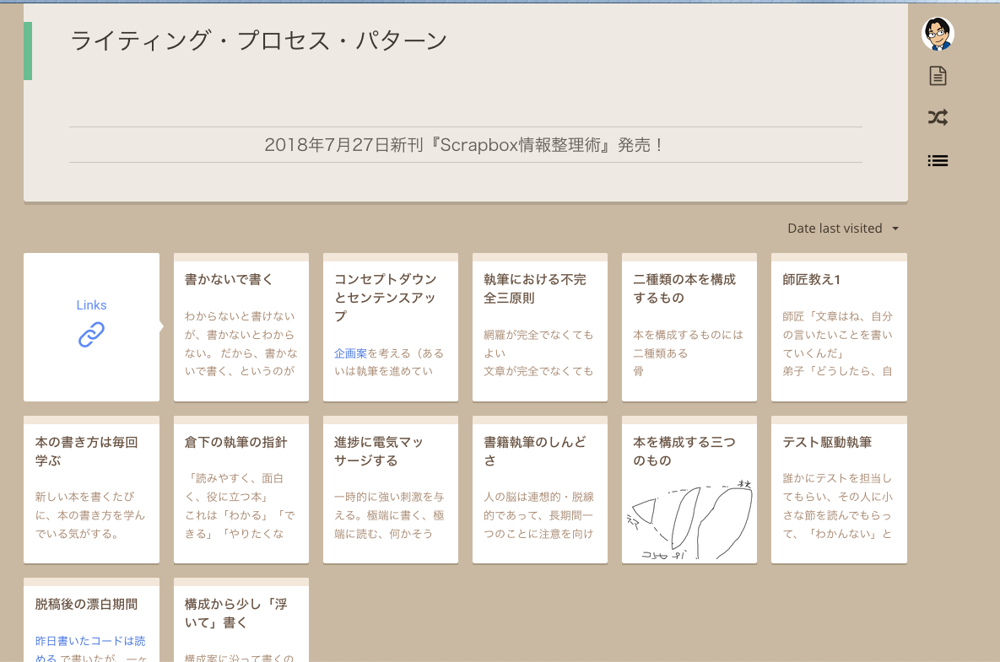
深呼吸を15回くらいして待つ(本当に時間がかかります)
取得が終われば、自動的に新しいウィンドウが開く。

すべてのテキストを選択して、コピー。
しかるのちにWorkFlowyにペーストします。

移行、完了。
注意点
[] (ブラケット)は削除されますおおもとのハッシュタグ(例で言えば
ライティング・プロセス・パターン )は削除されますそれ以外のハッシュタグは残ります
script.jsconst makepage = function () {
const url = location.href.replace("io/", "io/api/pages/");
let x = new XMLHttpRequest();
x.open("get", url, false);
x.send(null);
let json = x.responseText;
let pagedata = JSON.parse( json );
let relatedPagesData = pagedata["relatedPages"];
let relatedPagesDatalinks1hop = relatedPagesData["links1hop"];
//ループで回して、関連ページの本文を取得していく
let pageContents = [];
let rooturl = location.href.replace("io/", "io/api/pages/").replace(new RegExp("/" + encodeURI(scrapbox.Page.title) + "$"),"/");
for (let i = 0, len = relatedPagesDatalinks1hop.length; i < len; ++i) {
let relatedurl = rooturl + relatedPagesDatalinks1hop[i]["title"] + "/text";
//これでXMLHttpRequestを回していく
let y = new XMLHttpRequest();
y.open("get", relatedurl, false);
y.send(null);
let c = y.responseText;
c = removehashtag(c,scrapbox.Page.title); //もとハッシュタグを削除しない場合はこの行をコメントアウト
c = removebracket(c)//本文中からブラケット[]を取り除かない場合はこの行をコメントアウト
pageContents.push(addmargin(c));
}
//取得したページの中身を使って、新しいwindowをオープンする。
var win = window.open();
win.document.open();
win.document.write(`<title>temporary</title>`);
win.document.write('<pre>');
win.document.write(pageContents.join('\n'));
win.document.write('</pre>');
win.document.close();
}
function removehashtag(text,pageTitle){//本文中からもともとのハッシュタグを削除する
return text.replace(new RegExp('#' + scrapbox.Page.title),"")
}
function removebracket(text){//本文中から閉じと開きのブラケットを削除する
return text.replace(/\[|\]/g,"")
}
function addmargin(text){ //二行目以降に半角スペースを追加する
return text.replace(/\n/g,"\n ")
}
scrapbox.PageMenu.addMenu({
title: '関連ページ取得',
image: 'https://gyazo.com/da0408108eda84e56a587630be5e4524/raw',
onClick:makepage
})