プログラミングの変化勉強会
2023-02-10
先日、眼科健診の待ち時間で「この10年のプログラミング言語の変化」にツイートしたら予想以上に反響があった
箇条書きでまとめた上記ページは1万PV以上見られている
これをかんがえをまとめるデジタル文房具Kozanebaでまとめた
(先週Kozanebaにつけた手軽に線を引く機能の動作テストを兼ねて)
今日はそれをざっくり解説してから重要なポイントについてコードを交えて解説する
まずは全体像

これが本当の全体像

少しズーム
当初「この10年の間にあったプログラミング言語の仕様変更で大きなものってなんですかねー」という問いでスタートした
が、集まった意見を見るとどうも「プログラミング言語の仕様」という枠組みに収まらないものがある
一番大きなもの: ブラウザ
他には機械学習やコンテナ技術がこの10年でプログラミングというアクティビティに大きな影響を与えた
プログラミング言語の仕様の話に入る前にまずこれをざっと見る
ブラウザ

10年前の2013年にiPhone5Sが出た
その後10年でスマートフォンが普及した
スマートフォンアプリを作る仕事が増えた
一方でiOS向けとAndroid向けを個別に作るのは高コスト
WebView(ブラウザコンポーネント)でやろうという動きが生まれる
時を同じくしてデスクトップ環境にも似たことが起こっていた
2013年、Electron登場
GUIアプリケーションを、Windows、Mac、Linuxと作り分けるのは高コスト
ChromiumレンダリングエンジンとNode.jsで実現しようという動きが生まれる
これが現実的な選択肢であることがElectronベースで作られているMicrosoftのIDE「Visual Studio Code」(2015)で如実に示された
IDEのような複雑なものがまともなパフォーマンスで動く、ならばこれでいいじゃないか、となった
この10年で起こったこと
ブラウザの技術的進歩
これが「Webサービスの提供」という狭い範囲ではなく
「GUIの提供」という広い範囲に影響を与えた
Q&A
最近、InstaChordって電子楽器を買ったんですけど、これのファームアップデートの時にもうネイティブアプリなんかいらなくて、ブラウザからUSB接続した周辺機器と直接シリアル通信するの
>Web Serial API は、ウェブサイトがシリアルデバイスからデータを受信したり、シリアルデバイスにデータを送信したりする方法を提供します。対象は、シリアルポートで接続されたデバイスのことも、シリアルポートとして振る舞う USB や Bluetooth のデバイスのこともあります。MDN
10年前なら「Windowsでこのexeファイルを実行してください」とか言われてたようなことがもうOSと無関係にできちゃう時代
視線を戻す

大きなトピック3つある
やっばり型が欲しい
async/await
破壊的更新を避ける
破壊的更新を避けるプログラミングスタイルに関してはさらに様々な要素が絡んでいる
この講義資料を作ってる段階ではまだ整理し切れてないが、ざっくり見ていこう
(注: 図では「脱オブジェクト指向」が大きく表示されているが、これは「オブジェクト指向」という言葉でイメージするものが人によってマチマチな曖昧なフレーズなので避けることにした)
GUI開発と破壊的更新を避ける動き
破壊的更新を避けるプログラミングスタイルの話はGUIの話と結構関連している

かつてGUIはオブジェクト指向の重要な応用領域だった
個別のボタンは、ボタンクラスのインスタンス、個別のラベルは、ラベルクラスのインスタンス、…
GUIはオブジェクト指向のメリットを素直に理解しやすい応用ドメインだった
しかし10年前の時点でその使い方には変化の兆しがあった
>Java 周辺には「実装の再利用を目的とした継承」を避ける方 向への動きが見られます。たとえばグラフィックツールキットの実装がそ うです。1995年にリリースされたAbstract Window Toolkit(AWT)では「継承して各種メソッドをオーバーライドして使う」ルールでした。しかし、今 Eclipseなどで使われているStandard Widget Toolkit(SWT)は「継承してはいけない」というルールです。
> 代わりに発達したのが「委譲」の概念です
(コーディングを支える技術 p.222)
(余談: 文章に「今」と書いたのは失敗だったな、2023年の今の読者はEclipseがわからないかも…)
2019年、React「Hooks API」
プログラマが状態のあるGUIコンポーネントを定義する際に、クラスを使わない
代わりに状態を持たない関数を使う
この関数コンポーネントが、クラスコンポーネントと同等のことができるようにする仕組みがHooks API
関数コンポーネントの方を標準的な使い方とみなしていく
Hooks APIと関数コンポーネント
状態のあるGUIコンポーネント
「例えばクリックするとオンオフが切り替わるスイッチ」を考えてみよう
これは「オンオフ」が状態
クラスでコンポーネントを定義する場合、素朴に考えるとコンポーネントの状態はメンバ変数として持つことになる
関数コンポーネントでは、状態をReact側が持つ
Hooks APIと呼ばれる仕組みによって、状態の現在の値とsetterを取得する

状態を更新する時にはそのsetterを呼ぶ
状態の変更をReactに任せることで、コンポーネントの側が状態を持たなくなった、なので関数で良くなった
これの何が嬉しいのか
Reactの側が「状態が更新されたこと」を知ることができる
クラスがメンバ変数を書き換える実装スタイルだとフレームワークが変化を察知しにくい
特に過去のオブジェクト指向の考え方だと「メンバーをprivateにして外から見えないようにしよう」となりがち
Reactは「その状態を参照するコンポーネント」も知っている
その状態をReadしてきたコンポーネントだけがその状態に依存した振る舞いをする
再描画が必要なのはこのコンポーネントだけ

対象の関数コンポーネントをReactが呼び出し、その結果を使って再描画をする
Q: 状態を管理する責任を負わず、状態遷移の方法だけ記述する?
A: まあそうですね。状態管理をあちこちのオブジェクトが各自でやってるとカオスなわけです。なのでReactの一箇所にまとめる的な話
関数コンポーネントはHooks APIによって最新の状態を得てレンダリング結果(仮想DOM)を返す、状態を持たない関数として設計できるようになる
プログラマがちゃんと書けば副作用を持たない関数になる
つまり状態の更新回数と同じ回数呼ぶ必要がない
状態の更新と同期的である必要もない
例えばボタンを押すと101回オンオフが切り替わるコードを書いたとしても、レンダリングは1回だけ実行される、などということが可能になる
これがパフォーマンスに対して重要、これができるようにするためにみんな関数コンポーネントを使おうね、そうするともっと速くなるよ、という流れ
状態にも「永続化する状態」と「しない状態」がある
GUIにおける「状態」はどのテキストボックスにフォーカスが当たってるかとかも含んでいる
ブラウザ上のすべての状態をデータベースに送るのは現実的ではない
ブラウザ上にしかない状態も存在しているはず
Reactの状態の一部に関して更新をウォッチして、更新があったらデータベースに書き込みにいくという画面に表示されないコンポーネントがあってもいい
状態が更新されたときに、そのどれをデータベースに保存してどれを保存しないかはプログラマーのチョイス
Reactにすべての状態が集まっているから、その中の「永続化したい状態」が更新されたときに、それをデータベースに書き込みにいくって設計は、コンポーネントがバラバラに状態を持っているよりも実装しやすくなるだろう
具体例を追加
Kozanebaではドラッグドロップでの要素の移動は、ドロップのタイミングで全部データベースに保存している
Kozanebaでは要素をクリックするとコンテキストメニューが開く
この「どのメニューがどこに開いているか」もReactが管理してGUIのレンダリングに影響する「状態」
保存すれば、データベースの書き込みコストと引き換えに、次回の起動時に復元できる
これをデータベースに保存すべきだとは思わない。コストに見合うメリットがないから
状態が変われば再描画は必要
しかしそこが同期的呼び出しでは密結合すぎる
実際のところその密結合が必要か?
人間の目の時間解像度が低いからブラウザ上での表示の更新ディレイが多少あっても問題ない
非同期にすることで必要なくなる更新もある
だから「状態の書き換え」と「状態の書き換えにトリガーされた再描画」を切り離したかった
これがHooks APIを入れていく最大のモチベーションだったのではないかと僕は思う
リアクティブプログラミング系の流れ

名前がまちまち、概念にも揺れがある
説明できるほど詳しくないことに気づいたので今回は事実をざっと眺めるだけにする
2007 C# LINQ(Language INtegrated Query)
c#// Specify the data source.
int[] scores = { 97, 92, 81, 60 };
// Define the query expression.
IEnumerable<int> scoreQuery =
from score in scores
where score > 80
select score;
// Execute the query.
foreach (int i in scoreQuery)
{
Console.Write(i + " ");
}
// Output: 97 92 81配列などのコレクションに対してもSQLのようにクエリランゲージを書ける
2009~2011 C# Rx(ReactiveExtensions)
LINQの考え方が非同期処理に応用される
データベースと配列が「似たもの」として統一的に扱われるようになった流れの延長で、ストリームの概念を使って非同期処理を記述するようになった
2014 Java Stream API
java int sum = widgets.stream()
.filter(w -> w.getColor() == RED)
.mapToInt(w -> w.getWeight())
.sum();もちろん、各メソッドの呼び出しで大きな一時オブジェクトが作られたりはしない
2020 Java / C#: Record型
c#public record Person(string FirstName, string LastName);javarecord Rectangle(double length, double width) { }>レコード・クラスは一連のフィールドを宣言し、適切なアクセッサ、コンストラクタ、equals、hashCodeおよびtoStringメソッドが自動的に作成されます。このクラスは単純な「データキャリア」として機能することを意図しているため、フィールドはfinalです。
>この簡潔な宣言は、次の標準クラスと同等です:
javapublic final class Rectangle {
private final double length;
private final double width;
public Rectangle(double length, double width) {
this.length = length;
this.width = width;
}
double length() { return this.length; }
double width() { return this.width; }
// Implementation of equals() and hashCode(), which specify
// that two record objects are equal if they
// are of the same type and contain equal field values.
public boolean equals...
public int hashCode...
// An implementation of toString() that returns a string
// representation of all the record class's fields,
// including their names.
public String toString() {...}
}Q: すごく単純なstruct?
A: 破壊的更新が禁止されてるところがstructとの大きな違い
Q: 先に代入することができない?単純にデータをトランスファーするオブジェクト?
A: そう。そういうオブジェクトを作る手段が今まではたくさんコードを書かないと実現できなかった。
2009年とかの発展の過程で「ここを伝わるオブジェクトが破壊可能なのはおかしいよね」「破壊不可能なオブジェクトが手軽にかける手段が必要だよね」ということでJavaとC#が変わった
Q2: const dataってことですか
A2: そう言っていいと思います
Q3: ミューテックスだけは可変に持ちたいという欲が出てくると思う
A: ミューテックス周りのことは追いかけてないですね、わかりません
先ほどのReactで関数コンポーネントが仮想DOMを返していたのも同じ
ブラウザの生のDOMを人間が破壊的に更新することを避ける
仮想DOMを返す=新しいオブジェクトを作って返す
それを生のDOMに反映させる破壊的更新の作業は人間ではなくReactがやる
ざっくりまとめ
書き換え不能な(immutableな, finalな)「データキャリア」オブジェクトを受け取って、新しいオブジェクトを返す関数のつらなりとして物事を記述する
オブジェクトを破壊的に書き換えるのではなく、そういう方法を使おうという流れが生まれた
それを楽に記述するための方法が言語の側に入って行った
非同期処理関連ではこれが大きい

async関数はPromiseを返し、awaitはPromiseが解決されるまでブロックする
Promise(またはfuture)は古くからある考え方
1997年のE言語で今使われているような実装になった
この10年の間にC#、Python、ECMAScript、Rustなどが相次いでこのやり方を採用した
Promiseとはなんなのか
非同期処理を実行したタイミングでブロッキングせず即座に値が返される、これがPromise
「後で値を提供しますね」という約束
比喩より定義が見たい人にはこれ
>An open standard for sound, interoperable JavaScript promises—by implementers, for implementers.
Promiseは3つの状態を持つ

thenメソッド
jspromise2 = promise1.then(onFulfilled, onRejected);
非同期処理の表現方法には他にはコールバックを渡すとか、イベントハンドラを登録するとかがあった
js// callback style
do_something(params, on_success, on_error);jsr = new Request(params);
r.on_success = on_success;
r.on_error = on_error;
r.send()かつてのJavaScriptでは他のサービスのAPIを叩いたりするのに
XMLHttpRequest を使っていた、これはイベントハンドラを使うスタイルだったこれが面倒だったのでサードパーティライブラリが試行錯誤し、Promiseを使うスタイルがデファクトスタンダードになった
そのあとでPromiseを使うスタイルのAPIが標準化された
何が面倒だったか?色々あるが:
非同期処理をした後にやりたいことをソースコード上で先に書くのは思考の流れが混乱する
非同期処理1をした後、その結果を使って非同期処理2をして…と続けて行った場合のエラー処理
Promises/A+でこう定義されているので、1箇所にまとめて書くことができる
>IfonRejectedis not a function andpromise1is rejected,promise2must be rejected with the same reason aspromise1.
コールバックやイベントハンドラのスタイルでは、名前付きの関数にした上であちこちの
on_error にそれを指定することになる
動的型付けの言語が「やっぱり型が欲しい」と言い出して漸進的型付け(Gradual Typing)を導入した
例
pythondef foo(x: int):
y: str = x # NG error: Incompatible types in assignment (expression has type "int", variable has type "str") [assignment] 全部に型宣言を書きたくない
では型宣言の書いてないものは何か?
暗黙のany型
any型ってJavaの
java.lang.Object みたいな型?違います
pythondef foo(x: int):
y: object = x # OKpythondef foo(x: object):
y: str = x # NG error: Incompatible types in assignment (expression has type "object", variable has type "str") [assignment] Object型の値をString型の値に代入しようとすること(暗黙のダウンキャスト)はNG
これが普通の型の振る舞い
anyがアップキャストもダウンキャストも暗黙に行える特殊な型ということ


TypeScriptではこの二つの挙動に対応する型が unknownとany
tsconst take_number = (x: number): void => {};
{
let x: any;
take_number(x); // OK
}
{
let x: unknown;
take_number(x); // NG
} Argument of type 'unknown' is not assignable to parameter of type 'number'. 現状のPython(mypy)では返り値の型を推測しない
pythondef foo(x: int):
return x
print(typing.reveal_type(foo)) note: Revealed type is "def (x: builtins.int) -> Any" これはTypeScriptとは異なる挙動

人間がこう明示することが期待されている
pythondef foo(x: int) -> int:
return x
print(typing.reveal_type(foo)) note: Revealed type is "def (x: builtins.int) -> builtins.int" 名前的型付けと構造的型付け

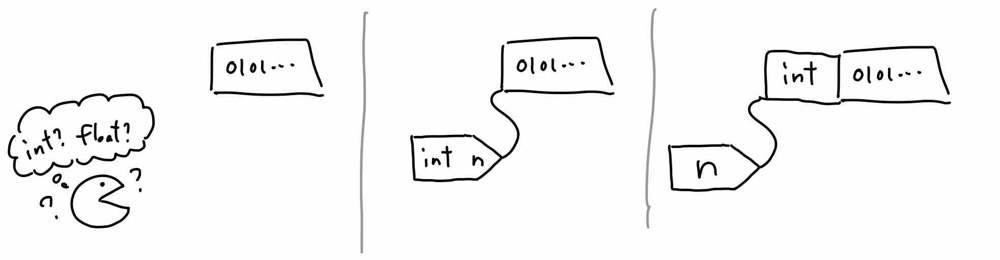
メモリに0と1が並んでいるだけでは、それが整数なのか浮動小数点数なのかわからない。
そこで
int n; などと宣言することで「これは整数だよ」という情報を変数につけるのが静的型付け「この値は整数だよ」という情報を値につけるのが動的型付け
この「変数にメタ情報をつけるアプローチ」に二つある
構造を使って判断する派
名前を使って判断する派

1985年に生まれたC++や1995年に生まれたJavaは名前的型システムを採用していた。
名前が異なるものには互換性がない
extends や implements で部分型関係の宣言をするこの2つの言語はとてもメジャーになったので、このやり方に慣れ親しんだ人も多いだろう。
一方、型理論の研究においては構造的型システムの方が主流だった。
その結果、JavaScriptを生成するための静的型付け言語を設計する際に、Javaなどを参考に名前的型システムを採用した言語(Dartなど)と、型理論を参考に構造的型システムを採用する言語(TypeScriptなど)が混在することになってしまった。
TypeScriptでの例
TypeScripttype T1 = {
x : number
}
type T2 = {
x : number
}
let a: T1;
let b: T2 = {x: 1};
a = b; // OKこのコードの
let b:T2 = {x: 1} の、 {x: 1} の部分は名前のないオブジェクト型である。これはT1ともT2とも同じ形をしているので、エラーになることなく代入できる。
構造の同じ型に違う名前をつけて、区別されることを期待してしまった事例
Rust: 所有権・ライフタイム
Rustは2010年にリリースされた
2015年にRust 1.0がリリースされた
2016年から2020年にかけてStack Overflowによる「開発者がもっとも愛するプログラミング言語」でRustが1位を取り続けた
Rustは所有権やライフタイムの概念が特徴的とされるが、所有権はRust特有の概念ではない
C++11で
std::unique_ptr が採用されているこれはつまり「確保したメモリを唯一指しているポインタ」
このポインタがスコープを抜ける時にはそのメモリを参照する手段がなくなるのだから解放してよい
C++は過去のコードとの互換性のために、従来通りのシンプルな記法は従来通りの挙動、新しい挙動には新しい記法、という縛りがある
Rustは違う言語になることでこの互換性の縛りから逃れる
rustlet x = String::from("hello");
let y = x;
println!("x: {}", x); // NG
println!("y: {}", y); error: borrow of moved value: x xやyがC++でいうところのunique_ptrになっていて、
y = x でムーブが行われているC++では普通は参照のコピーをしようとしてしまう
「コピーではなくムーブを意図しているんだ」と表現するために
std::move を使うこれを既存のコードを壊さずに実現するために「右辺値/左辺値」の区別がC++11で追加された
「ある値が右辺値であるなら、今後使わないのでコピーではなくムーブでよい」ということ
こうして右辺値参照を受け取るムーブコンストラクタが追加された
std::moveは右辺値参照にキャストすることでムーブが行われるようにする
C++においては「有効でないポインタをデリファレンスしないように気をつける」はコンパイラの仕事ではない
人間が気をつけるか、静的解析ツールでチェックする
Rustではコンパイラがそれをチェックする
上記のRustコードと同じことをC++でやろうとしたらSegmentation faultになってしまった
cpp#include <iostream>
#include <string>
#include <memory>
int main () {
std::unique_ptr<std::string> x = std::make_unique<std::string>(std::string("abc"));
std::unique_ptr<std::string> y;
y = std::move(x);
std::cout << *y << std::endl;
std::cout << *x << std::endl; // here
}outputabc
Segmentation faultこのコードでは、間違って読んだり解放したりしてしまわないようにxはnullになっている
「スコープを抜けた時に解放されるのはRAIIと同じでは?何が珍しいの?」と思ってた
重要なのは「シンプルな書き方をした時にmove」というデフォルト挙動の変化の方だと思う
例
rustlet x = String::from("hello");
foo(x); // move
println!("x: {}", x); // NGこの例では関数呼び出しのところでxがムーブしているからそれ以降使えない
代入によるムーブや関数呼び出しによるムーブをたどっていって「ムーブせずにスコープを抜けたところ」で解放をするようにコンパイラがやってくれる
ライフタイムの概念
参照が有効であるスコープ
スコープという言葉の今を多くの人がソースコード上のブロックと関連付けて考えるので(字句的スコープだと解釈するようになったので)スコープと呼ぶと混乱が起きる
呼び出し元で作られた参照が呼び出し先でも有効である特徴はPerlなどにあった動的スコープに似ている
rustlet x;
let y;
// println!("x: {}", x); // NG
// error[E0381]: used binding `x` is possibly-uninitialized
x = String::from("hello");
println!("x: {}", x); // OK
y = x;
// println!("x: {}", x); // NG
// error[E0382]: borrow of moved value: `x`xの初期化前とムーブ後の利用がコンパイルエラーになることがわかる
ライフタイム指定子
ライフタイムをコンパイラが推測できない時に教えてやる記法
独特な記法に戸惑う人も多いみたい
これは変数に対してメタデータを付与する行為なので広い意味で「型」
ライフタイム指定子が「名前をつけなければいけない」ので慣習的に
'a とつけるのは、ジェネリクスで型変数に T と名前をつけるのと同じ名前自体に意味があるのではなく同じ名前が複数箇所で使われることによって、その要素の間の関係を表現する
例1
複数の参照に同じ名前のライフタイム指定子をつけると、その共通部分集合がライフタイムになる
rustfn longest(x: &str, y: &str) -> &str { // NG
if x.len() > y.len() {
x
} else {
y
}
}errorerror[E0106]: missing lifetime specifier
--> src/main.rs:14:33
|
14 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
14 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++例2
staticライフタイム
あらかじめシステムによって名前が付いているライフタイム指定子
「プログラム全体にわたるライフタイム」を表現している
rustfn dangle() -> &String {
let s = String::from("hello");
&s
}errorerror[E0106]: missing lifetime specifier
--> src/main.rs:22:16
|
22 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime
|
22 | fn dangle() -> &'static String {
| +++++++これは本来はダメ
関数を抜ける時にsが解放されるから
なんだけどコンパイラが「定数に変えたらプログラム全体をライフタイムにできるな」と判断してる
その結果2歩先を行くエラーメッセージになってる
コンパイラが定数にできるかわからないようにしてやれば素直なエラーメッセージになる
rustfn dangle(x: &String) -> &String {
let s = x.clone();
&s
}errorerror[E0515]: cannot return reference to local variable `s`
--> src/main.rs:31:5
|
31 | &s
| ^^ returns a reference to data owned by the current function