NoSQL
定義が広い/曖昧?
2009: リレーショナルデータベース以外のデータベース(全て)を指す用語として定義された
BASE特性を持つ
強み
データ容量が大きい(大量のデータを扱える)
分散システムを基本とするから️
スケーラビリティが高い
システム管理コストを下げられる
従来DBA(管理者)が行っていたバックアップ作業等を自動で行う
(分散システムの仕組み上自動でせざるをえないから、そういう機能が提供される)
設備投資コストが低い
柔軟、様々なモデルを扱える
弱み (大体は歴史の浅さが原因)
発展途上のシステム
重要な機能が未実装だったり
サポート体制が整備されていなかったり
多くのシステムはOSS、即座に不具合に対応してもらえないことも
システム管理に高いスキルが必要
プログラミングコストが高い、SQLのように標準化されてない?から使う物に合わせないといけない?
専門家が不足している
NoSQLのアーキテクチャ: 分散データベース
様々なデータモデルが存在する(「NoSQL」はSQLでないというだけの言葉なので)
これらの違いは、Aggregateの形
例
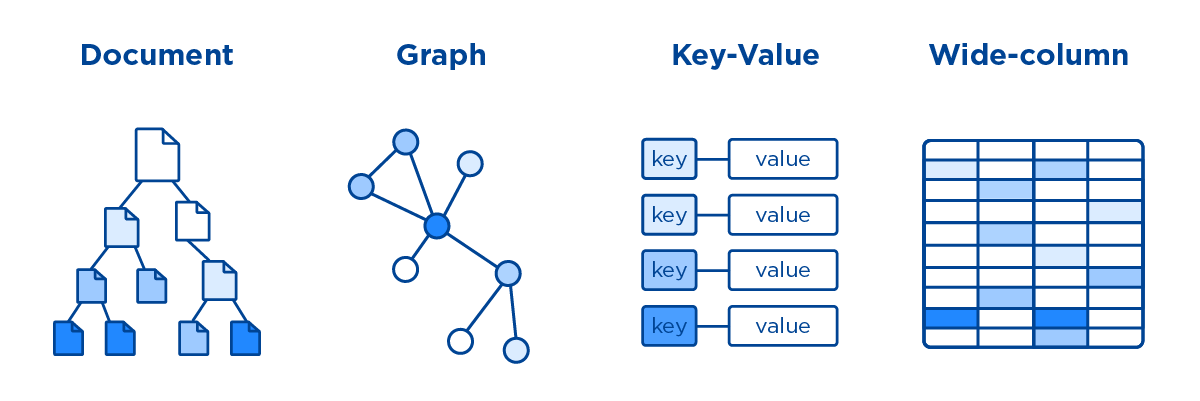
KVS (Key Value Store)
向いているユースケース
Keyのみで情報が一意に特定できる場合
ex: ユーザ情報, 商品情報などの参照, 更新
向いてないユースケース
複数のaggregate(key-value pair)の集合演算をしたい場合
valueから検索したい場合
スキーマレスな半構造データ
kvsの、valueに対して別のaggregateを置けるようにした物
ネストさせている
向いているユースケース
スキーマが固定されていないデータの場合
ex: イベントロギング, ブログ記事, eコマース
向いてないユースケース
複数のaggregateの集合演算をしたい場合
データ構造が定期的に変わる場合 ( なぜ?)
なぜ?)
ドキュメントデータベースとリレーショナルデータベースの中間的な
rowの中にcolumnがある
ただ、リレーショナルデータベースみたいに全rowが同じcolumnを持つ必要はない
向いているユースケース
スキーマが多くの場合同じだけど、たまに異なることもある場合
ex: イベントロギング, コンテンツ管理システム, ブログ管理システム
向いていないユースケース
ACID特性が求められる場合
問合せ処理結果の集約演算が必要な場合
プロトタイプ(クエリパターンが変わりやすい)の場合
データをグラフとして管理
エンティティ間の関連性を保存する
向いていないユースケース
大規模なバッチ処理が必要な場合
巨大なグラフデータを扱う場合
スケーラビリティ確保が難しい
なぜなら、NoSQLでよくやる手段(データを分割して分散させる)がやりにくいから